Part 2: Qualitative Data Infrastructure and Research Methods
In Part 1 I talked about my experience using quantitative research methods at the MBTA. Over the past almost a year I have thought (and read) more about qualitative research and data (and the difference between the two).
For transit agencies to really consider and use community voices and lived experience as data they will need to institutionalize qualitative data and research methods. This will require different data infrastructure, data collection, and analysis skills.
In general transit agencies gather qualitative data for a particular project, plan, or policy decision as one-off efforts. Each effort sometimes regathers the same input from the community as previous ones. This can be a burden on both the community and the agency’s time. Part of the problem is that transit agencies (transportation more widely) don’t have a qualitative data infrastructure.
As agencies started getting more automated data from technology systems they developed data infrastructure to clean and store data. They hired IT staff to build and maintain data warehouses and data scientists to analyze the data. They built dashboards that visualize the data. Part of what this data infrastructure allows is for multiple teams to use the same data to answer different questions. For example, ridership data is stored in one place and many departments (and agencies and organizations) can access it for their analyses. The data infrastructure also provides transparency with open data.
In my experience transportation agencies don’t have the same infrastructure for qualitative data. There isn’t a centralized location and a storage system so multiple teams can find out what riders on a certain route or neighborhood are saying. The data from the customer call center remains siloed in that system. The input for a specific project stays with that project team. Data from the transit agency isn’t shared with the MPO or City. Or the public in a standardized way.
At the MBTA we did create an infrastructure for survey data. My team wrote an internal survey policy to standardize practices and data sharing. Part of this effort was standardizing basic questions so we could gather comparable results across surveys and time. This ‘question bank’ also allowed us to save time and money by getting all of our standard questions translated into the six languages the MBTA uses (based on its Language Access Plan) once. We attempted to create a single repository for survey data. (Most of the work to do this was organizational, not technical.)
Creating this type of qualitative data infrastructure requires thinking through data formats, how to code qualitative data (by location, type of input, topics, etc), and how to share and tell the stories of the data. And whoever is doing that has to have authority to impact all of the ways the agency gets community input. So importantly creating this infrastructure is also about where community engagement lives in an agency and how it is funded.
(An advocate I spoke to recently suggested that maybe this consolidation of qualitative data shouldn’t even live at a transit agency. That it should cut across all transportation modes and live at the MPO or other regional body.)
To move beyond using qualitative data in quantitative analysis, agencies need people with research and data collection skills not always found in a transit agency. Lots of agencies have started hiring data scientists to analyze their ‘big’ quantitative datasets. Agencies also need sociologists, ethnographers and other research skillsets grounded in community. These researchers can design community data collection efforts that go beyond public comments in a public meeting.
Qualitative research also asks different questions. Instead of using data to explain who is in the tail of a quantitative distribution, qualitative research asks questions like why is the distribution like this in the first place and how do we change it. Qualitative research is able to bring in historical context of structural racism, explore the impact of intersectional identities, and allows power dynamics to part of the analysis. Check out more from The Untokening on the types of questions that need to be asked.
Transit agencies often aren’t asking the types of research questions that qualitative research answers. Not just because they don’t have the staff skillsets, but because these questions don’t silo people’s experiences with transit from their experiences and identities overall. Lots of agencies try to stay in their silos, so they aren’t forced to address the larger structural inequities. It is easier to focus on decisions you think are in your control. For example, quantitative Title VI equity analyses are confined to only decisions made by that agency in that moment in time. But equity is cumulative and no one is just a transit rider.
Valuing community voices as essential data means agencies will need to invest in data collection, storage, analysis, and visualization or story-telling for qualitative data in a manner similar to quantitative data. The executive dashboards and open data websites will need to incorporate both types of analysis and data. More fundamentally it means that agencies will have to breakdown their silo and take an active role in fixing the larger structural inequalities that impact the lives of their riders everyday.
This series is about the data used to make decisions; clearly who is making the decisions is also important to valuing community voices. I chose to write this series in a way that shows how my thinking about data has evolved over time and will no doubt continue to do so. In fact it evolved in the act of writing this! For insightful dialogue about revision in writing and life, check out this podcast between Kiese Laymon and Tressie McMillan Cottom.
Part 1: Mixing Qualitative Data into Quantitative Analysis
One of The Untokening Principles for Mobility Justice is to “value community voices as essential data.” I have been thinking about how transit agencies can put this into practice.
This is a three-part series that shows my thinking about data over time. The prequel is the post I wrote on data back in 2017 that mostly focused on how messy quantitative data analysis is. In Part One I discuss my experience in a transit agency mixing quantitative and qualitative data for analysis using quantitative research methods. Part Two is my thinking now on the importance of qualitative research methods and what transit agencies need to do to put qualitative data on equal footing with quantitative data. (Note: I have found a distinction between qualitative data and qualitative research methods useful as my thinking has evolved.)
Quantitative transit data often comes from technology systems (e.g. automated passenger counters or fare collection systems) or survey datasets (e.g the US Census or passenger surveys). In both cases collecting quality data requires investment. The benefits of technology systems are datasets that contain almost all events (a population, not a sample) and the ability to automate some analysis. However, transit agencies can’t rely on technology systems alone, because there is so much information, quantitative and qualitative, that these systems can’t measure.
As a generalization, qualitative data is information that is hard to turn into a number. For quantitative transit analysis, it is needed to answer questions about how people experience transit, why they are traveling, trips they didn’t make, and how they make travel decisions. Qualitative data can come from surveys, public comments at meetings, customer calls, focus groups, street teams, and other ways that agencies hear from the public directly.
In the data team at the MBTA we knew we needed both quantitative and qualitative data, usually mixed together iteratively depending on the type of decision. As an oversimplification, we used data to measure performance, find problems, and to identify/evaluate solutions.
Before you measure performance, you have to decide what you value (what is worth measuring) and how you define what is good performance. Values can’t come from technology and should come from the community. At the MBTA the guiding document is the Service Delivery Policy. In our process to revise this policy, we used community feedback in the form of deep-dive advisory group conversations, a survey, and community workshops. Once we agreed on values, knowing what data we had to measure those values, we needed input to try to make the thresholds match people’s experiences.
For example, we valued reliability so wanted to measure that in order to track improvements and be transparent to riders. This brings us to the question of how late is late? Our bus operations team stressed that they need a time window to aim for due to the variability on the streets. From passengers we need to know their experiences like: is early different than late, do they experience late differently for buses that come frequently vs infrequently, and how they plan for variability in their trips. Then we worked with the data teams to figure out how to build measures using the automated vehicle tracking data to report reliability and posted it publicly every day.
Identifying problems can come from both community input and data systems. Some problems can only be identified through hearing from passengers. No automated system measures how different riders experience safety onboard transit or tells transit agencies where people want to travel but can’t because there is no service or can’t afford it. In some cases, automated data is far more efficient in flagging issues and measuring the scope and scale of problems. For example, we used automated systems to calculate passenger crowding across the bus network and where it is located in time and space.
The MBTA used quantitative data to identify a problem of long dwell times when people add cash to the farebox on buses. The agency decided on a solution of moving cash payment off-board at either fare vending machines (FVMs) or retail outlets. (I will admit more qualitative analysis should have been done before the decision was made.) It was critical to understand how this decision would impact the passengers who take the 8% of trips paid in cash onboard. We used quantitative data on where cash is used to target outreach at bus stops. We did focus groups at community locations. Talking to seniors we found that safety was a key consideration between using a bus stop FVM or retail location. This is the type of information we could have never gotten from data systems or survey that didn’t ask the right questions. The team used the feedback to shape the quantitative process for identifying locations.
A key question is at what points in a quantitative analysis process can agencies rely on quantitative data and when is qualitative data imperative. As a generalization, quantitative research methods aggregate data and people’s experiences. We aggregate to geographic units (e.g. census blockgroups) and to demographic groups. We look at the distribution of data and report out the mean or some percentile. Quantitative data analysts need to look at (and share) the disaggregate data by demographics/geography before assuming the aggregated data tells the complete story. And ask themselves, when do we need more data to understand the experience in the tail of the distribution and when is the aggregated experience enough for making a decision.
The question of the bus being late and the use of cash onboard illustrate this difference. Once we set the definition of reliability, service planners use quantitative data to schedule buses. Looking at a distribution of time it takes a bus to run a route, you know there is going to be a long tail (e.g. long trips caused by an incident or traffic). Even though the bus will be late some percent of the time, it is an efficient use of resources to plan for a percentile of the distribution. Talking to the people who experience the late trips would be useful, but likely wouldn’t change that service is planned knowing some trips will be late. (Ideally riders, transit agencies, and cities work together to reduce the causes of late trips!)
However, on the question of cash usage, looking at the payment data you can’t ignore the 8% of trips paid in cash. The experience of that small group of riders is critical. Likely riders paying in cash rely on transit, experience insecurity in their lives, and a decision to remove cash onboard is a matter of access. Without talking to riders, we have no data on why they pay in cash, what alternative methods to add cash would work best for them, and the impact of having to pay off-board.
In my current thinking, at a minimum, decisions that impact the ability of even a small number of people to access transit or feel safe require a higher threshold of analysis. Agencies shouldn’t rely solely on aggregate quantitative data and need qualitative data on the impacts. The role of transit (and government in general) is to serve everyone, including, and often especially, people whose experience fall in the tail of a distribution. (A very quantitative analysis view of the world, I know.)
The lived experience of the community is critical to transit agency decision-making. There are many types of data that can’t come from automated systems. In my experience transit agencies should mix qualitative data into quantitative data analysis, often iteratively as the data inform each other. In practice this means that the teams doing quantitative analysis and community engagement need to be working in tandem with the flexibility to adjust as new data changes the course of the analysis.
Prequel: Data Thoughts
(Written May 2017)
Data driven decision-making is the buzz phrase in government and with all the ‘big data’ available it has great potential to improve outcomes. But I don’t think most people have a good idea about what it means in practice or how to understand its limits.
The irony is that I studied pure math in college because I wanted absolutes and to find a kind of truth. I loved proofs, because there is an indisputable answer. And now I spend my days wading around in data, which is all some amounts of wrong, and trying to figure out how to best use it to guide decisions.
Here are a few overly simplistic conclusions I have drawn from my team’s work over the past two years.
Data isn’t clean
There is a tendency to think numbers are true, but in reality they are estimates. The challenge is figuring out how close of estimates and how to make them closer. Often the data we have isn’t being generated to measure the thing we want to measure; it is a byproduct of a different process we are trying to recycle.
We constantly have what we call ‘data mysteries.’ This is when common sense makes us think the data is missing or wrong, and we have to figure out the cause of the problem. Maybe there are software problems. Or we miscoded something along the way. Or the data just isn’t being collected in the way we thought.
Context is critical
Making information out of data requires a lot of context. We can’t find the problems with the data without knowing how the data was collected and the directions of possible errors. We need to know external variables that could be causing change.
We need to understand the problem we are trying to solve so we can identity the best datasets and types of analysis to answer that question. This determines the exact variable, the levels of aggregation, the timeframe for the dataset, and any number of other factors.
Lastly, the results require context. We might say that approximately 34% of trips won’t be impacted, but this will require four footnotes to explain the exact conditions under which we think this to be accurate.
Data analysis isn’t linear
It would be nice if the process went something like: define a problem, find clean data, analyze it, propose best solution. But it isn’t a linear process. Sometimes we find data and play around with it to see if it can tell us something interesting. Other times we have a problem and we don’t have data, so we try to collect some or find something that might approximate it. Often there is already a proposed solution and we are trying to check the impacts.
Analysis is a maze (if not, you are probably presupposing the answer). We are constantly making the best guess of which pathway to take, running into dead ends, finding data problems, and when we arrive at an answer it is likely only one of many paths. We can hope that no matter what path we took that the general conclusions would be the same; but, depending on the dataset, it isn’t a guarantee.
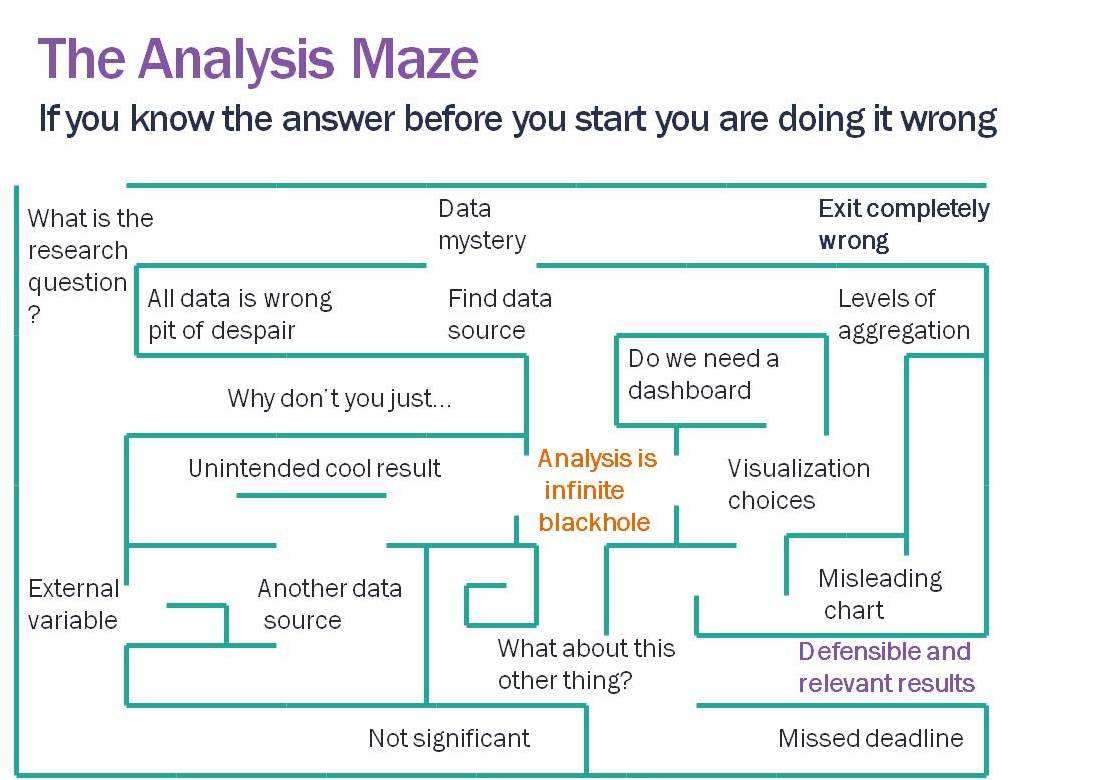
The results aren’t static
Just like writing there are drafts, but eventually we declare it good enough. And often there are mistakes. New data shows up which points out a problem with our original dataset. We figure out a new method. We realize we missed something or made a formula error.
We can hope we are at least asymptotically approaching ‘the answer.’ But we need room to get there. Being honest about data requires forgiveness.
Data isn’t everything
Our understanding of problems to be solved shouldn’t be limited by the data we have. And just because we have data on something doesn’t mean there is a problem to be solved with it.
For example, it is easier to estimate people’s wait times on subway platforms than at bus stops. But that doesn’t mean subway wait time reliability is more important than bus. Qualitative data (aka actually talking to people) is critical to finding problems and solutions.
We have all sorts of systems that generate millions of records of data a day. But the existence of data doesn’t eliminate the need to have a conversation about whether/how we should be using it.
Data literacy
Data does have the power to help governments to make better decisions. We can measure impacts of policy decisions. We can disprove conventional wisdom. The results can change (and improve) outcomes. In order to have this impact, decision-makers, members of the public, and journalists all need to be better data consumers.
This means reading the warning labels that come with a dataset to understand the context. It means appreciating all of the complexities and uncertainty in the process. It means allowing the time and space to find mistakes. But most of all, it means being open-minded and not allowing our implicit assumptions to overwhelm our curiosity about what the data can tell us.
Data is not a truth, it is very messy. But acknowledging and appreciating the mess makes the analysis far more likely to be accurate in the end.
