Prequel: Data Thoughts
(Written May 2017)
Data driven decision-making is the buzz phrase in government and with all the ‘big data’ available it has great potential to improve outcomes. But I don’t think most people have a good idea about what it means in practice or how to understand its limits.
The irony is that I studied pure math in college because I wanted absolutes and to find a kind of truth. I loved proofs, because there is an indisputable answer. And now I spend my days wading around in data, which is all some amounts of wrong, and trying to figure out how to best use it to guide decisions.
Here are a few overly simplistic conclusions I have drawn from my team’s work over the past two years.
Data isn’t clean
There is a tendency to think numbers are true, but in reality they are estimates. The challenge is figuring out how close of estimates and how to make them closer. Often the data we have isn’t being generated to measure the thing we want to measure; it is a byproduct of a different process we are trying to recycle.
We constantly have what we call ‘data mysteries.’ This is when common sense makes us think the data is missing or wrong, and we have to figure out the cause of the problem. Maybe there are software problems. Or we miscoded something along the way. Or the data just isn’t being collected in the way we thought.
Context is critical
Making information out of data requires a lot of context. We can’t find the problems with the data without knowing how the data was collected and the directions of possible errors. We need to know external variables that could be causing change.
We need to understand the problem we are trying to solve so we can identity the best datasets and types of analysis to answer that question. This determines the exact variable, the levels of aggregation, the timeframe for the dataset, and any number of other factors.
Lastly, the results require context. We might say that approximately 34% of trips won’t be impacted, but this will require four footnotes to explain the exact conditions under which we think this to be accurate.
Data analysis isn’t linear
It would be nice if the process went something like: define a problem, find clean data, analyze it, propose best solution. But it isn’t a linear process. Sometimes we find data and play around with it to see if it can tell us something interesting. Other times we have a problem and we don’t have data, so we try to collect some or find something that might approximate it. Often there is already a proposed solution and we are trying to check the impacts.
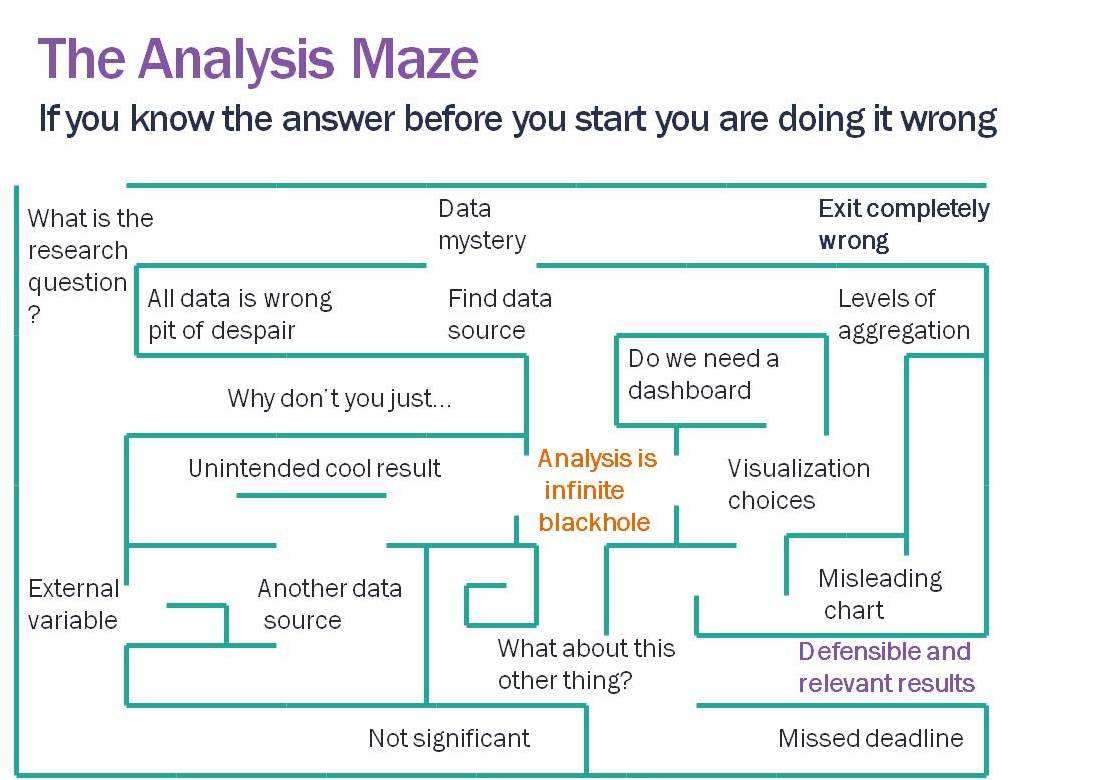
Analysis is a maze (if not, you are probably presupposing the answer). We are constantly making the best guess of which pathway to take, running into dead ends, finding data problems, and when we arrive at an answer it is likely only one of many paths. We can hope that no matter what path we took that the general conclusions would be the same; but, depending on the dataset, it isn’t a guarantee.
The results aren’t static
Just like writing there are drafts, but eventually we declare it good enough. And often there are mistakes. New data shows up which points out a problem with our original dataset. We figure out a new method. We realize we missed something or made a formula error.
We can hope we are at least asymptotically approaching ‘the answer.’ But we need room to get there. Being honest about data requires forgiveness.
Data isn’t everything
Our understanding of problems to be solved shouldn’t be limited by the data we have. And just because we have data on something doesn’t mean there is a problem to be solved with it.
For example, it is easier to estimate people’s wait times on subway platforms than at bus stops. But that doesn’t mean subway wait time reliability is more important than bus. Qualitative data (aka actually talking to people) is critical to finding problems and solutions.
We have all sorts of systems that generate millions of records of data a day. But the existence of data doesn’t eliminate the need to have a conversation about whether/how we should be using it.
Data literacy
Data does have the power to help governments to make better decisions. We can measure impacts of policy decisions. We can disprove conventional wisdom. The results can change (and improve) outcomes. In order to have this impact, decision-makers, members of the public, and journalists all need to be better data consumers.
This means reading the warning labels that come with a dataset to understand the context. It means appreciating all of the complexities and uncertainty in the process. It means allowing the time and space to find mistakes. But most of all, it means being open-minded and not allowing our implicit assumptions to overwhelm our curiosity about what the data can tell us.
Data is not a truth, it is very messy. But acknowledging and appreciating the mess makes the analysis far more likely to be accurate in the end.
