My Equity Change-Making Zine
Perhaps you have heard of it, maybe you even have a paper copy with a green cover, or most likely you have no idea what I am talking about. Anyway I wrote a zine on equity change-making at transit agencies (that probably applies to other government agencies) and in 2022 I released it only on paper like a proper zine. But now that equity change-making is even more under attack, I am releasing it digitally for all the folks still hunkered down doing the work in government agencies.
So here it is! Please share with whomever could use it, because I know change-makers in government need all the support we can give them right now.
Explaining the problem of run-times
Hi longtime readers and people stumbling over this site while googling how to transform transit or mix qualitative and quantitative data. It has been a while since I posted anything here, but I do have some new posts on the site of Public Advocates, where I am working as a transportation policy advocate.
It has been a bit of a transition to go from working in an agency back to being an advocate. When I see transit agency Board presentations I still find myself thinking how I would have presented the same material. One of the biggest differences is that I no longer have any positional power or a title from which to leverage my opinions. But my years inside did give me an advocate super power since I can sometimes see through the opaque agency walls to understand what is going and translate the agency lingo.
Right now I am working with bus operators and transit riders in the East Bay to engage with AC Transit’s service realignment planning process. I wrote a post explaining the building blocks of transit planning and scheduling and how the decisions impact bus operators. And I wrote a post that tries to illuminate the disconnect between what the agency Board is hearing from planners and from bus operators on the issue of adequate schedules.
Transform Transit has arrived!
Many years in the making, Transform Transit the board game was available for purchase (sale is over).

For the unfamiliar, Transform Transit is a cooperative board game simulating running a transit agency. The team tries to complete improvement projects while dealing with daily events. The constraints are bureaucratic bottlenecks, player morale, and general chaos. With some strategy (and luck), you can improve service and increase agency capacity!
The game was conceived as an educational tool, morphed into an emotional outlet, reworked to include more collective strategy, and tested at every stage. Thanks to my co-creator, colleagues, graphic designer, folks who play-tested it, and the OSF Leadership in Government fellowship for support.
The game is priced at cost and released under a creative commons copyright. You can make your own version! My goal is to start conversations about the challenges of policy implementation and what it will take to fix our government agencies to better serve the public and be good places to work.
We need to talk about how we talk about transit
This post builds off David Zipper’s article “How to save America’s public transit system from a doom spiral”. Yes, I know I missed the two-day lifecycle of stories on the internet, but I was busy. This is also in reaction to the framing for transit funding I have been hearing at presentations about the transit fiscal cliff in California.
I trust that most of my readers will agree that we need to save transit from a doom spiral. So the question is how we build the political support for new funding sources. I am wary of the narrative I am reading/hearing of curtailing congestion and replacing car trips as the way to build support for transit funding. It is too narrow a frame in two regards. First, we need an inclusive narrative to build the large coalition needed to support transit right now. Second, we need a narrative that allows us to shift the conversation to include both the benefits of transit and the costs of driving.
My frame is that transit should be competitive with driving. By this I mean transit should be a reasonable choice compared to driving for most trips people take in relatively high-density areas. There are lots of conversations to have about how to measure this, my former colleagues at the MBTA proposed some ways. At a high level I am considering comparisons on time, financial cost, safety, and comfort.
Talking about transit as competitive is more inclusive than talking about transit replacing car trips. Transit should be a good option for everyone, especially for people without cars! Speed, frequency and reliability are important, and so are network design and span of service.
Framing the argument for transit as replacing car trips impacts decisions around the design of transit networks. Using this argument, resources are put into service that cater to drivers (historically, the peak work trip) and not the needs of current transit riders. I wrote my dissertation on this 13 years ago[1]. Even before the pandemic, the majority of trips people made were non-work trips. The pandemic gave us an opportunity to reorient transit service away from the peak work trip to meet travel needs more broadly. Let’s not lose this moment by reverting back to the transit is needed to reduce congestion argument. That argument was used for years, with limited success in increasing ridership and negative impacts on service for transit’s core riders.
In my thinking, the reverse is true: traffic congestion drives up transit ridership because congestion increases the time cost of driving allowing transit using dedicated lanes and rails to be competitive. (Congestion is a major reason why before the pandemic commuter rail ridership was surging and bus ridership was declining.) We should improve off-peak transit to make it a better option compared to driving on non-congested (and over-built) roads.
Another problem with framing the need for transit by talking about the people not riding it is we forget that people are riding transit. Ridership hasn’t fully recovered, but there are still millions of transit trips being taken every day in the U.S. Transit is working to get people to jobs, school, doctor’s appointments, grocery shopping, and social events. Transit isn’t failing; the funding model and focus on serving peak office work trips is failing. And if we don’t shore up funding, millions of people will be impacted. This isn’t abstract; poverty and unemployment will go up, social isolation will increase. (Also ridership isn’t the best metric for the benefits of transit.)
‘Transit should be competitive’ is also a good framing because it allows us to consider the cost of driving and the cost of transit in a single framework. Realistically if we want transit to be competitive with driving we need to increase the cost of driving (in time and money) and reduce the costs (mostly time) of transit. This means bus lanes, transit signal priority and other relatively low capital cost ways to speed up transit. And it potentially means making the cost of driving more expensive – parking costs, gas, congestion pricing, etc.
We are spending a lot of time talking about whether we should make transit free or means-test fares for low-income riders. We need to flip this conversation (h/t to Tom Radulovich at Livable City) and talk about raising the cost of driving and means-testing to reduce the cost for low-income drivers. And we should keep transit fares low or free depending on the circumstances (there is not a one-sized fits all fare policy) because we want everyone to take transit.
Safety is important. Transit is statistically competitive in regard to safety, but the prevailing narrative around transit and perceptions of safety doesn’t convey this. Riding transit is safer than driving or riding in a personal vehicle. Never concede that transit is the unsafe option! It allows decision-makers to continue to ignore just how unsafe driving is (particularly for people who are not riding in vehicles). My biggest risk as a transit rider comes from crossing the street to get to the bus stop, not other riders. Transportation advocates need our narratives to match the real risks so we can get the policy attention on the right things. And the biggest transportation safety problem right now is posed by motor vehicles and their drivers, often going too fast. We need policies to slow down driving, which will have the side benefit of making transit more competitive.
A lot of the transit safety conversation is actually about the discomfort and fear that comes from being in proximity to people whose actions we cannot control or always predict. To ride public transit is to come face to face with a wide cross section of society. Some of our discomfort arises from not wanting to, or knowing how to, process seeing that our society is persistently failing people. Transit is the site of this discomfort because it is one of the remaining truly shared public spaces in our society.
Transit agencies need assistance from other parts of government to address homelessness, mental health, and drug addiction with methods that center crisis care and prevention, and not enforcement and criminalization. This assistance is needed for the people in crisis, to increase comfort (and in some cases safety) for other riders, and for the well-being and safety of frontline transit employees. Addressing the root cause of these issues requires major policy change outside the control of transit agencies. Transit agencies do have a role to address harassment and other harmful behaviors on their services and should let impacted riders lead the way (see BART Not One More Girl).
I know all of this: more transit service, bus lanes, increasing the cost of driving, honestly addressing the safety risks of driving, is politically difficult. Due to a long history of land use and transportation decisions, drivers are now a powerful multi-racial, multi-class, cross party coalition in U.S. politics. And unfortunately, as the cost of car ownership increases and, in some parts of the U.S., housing becomes more expensive near high-quality transit, more people who can’t afford vehicles are stuck driving. (For transit to be competitive transit riders need to be able to afford to live near it.)
To overcome the ingrained power of drivers, transit needs a big coalition. We need the people currently taking transit who want better service. We need the drivers who want a reasonable alternative. We need the drivers who can’t comfortably afford their cars but are stuck without other options. We need the climate and environmental justice activists and the people working for more housing in US cities. And yes, we do need the people who want less traffic for themselves.
We need to frame the conversations about transportation to focus attention on the problems and get us to the solutions we need. Transit should be competitive provides a framework for transit that works for all types of riders, and recognizes that the costs, including safety, of driving need to be part of the conversation.
Finally, we need to lift up the ways transit is working. Our narratives should focus on the people currently riding (remember the essential workers). We should talk about how safe transit is compared to driving. Transit in the U.S. isn’t half empty, it is more than half full!
[1] The Twin Cities showed up as very high in work trip usage in my dissertation dataset. So I went and interviewed the planners at Met Council to ask why and they said because we designed the network to do that. Twin City Metro ridership in 2022 was 50% of 2019 ridership, below the national average of recovery.
Introducing TransitDataPrimer.org
I spent a lot of time with my team at the MBTA/MassDOT thinking about how to think about data: about what data we had and the data we didn’t, the decisions we made in the analysis and visualization process and their implications, and how to communicate with different audiences about our level of certainty. I left knowing we needed better tools for the public, transit advocates, and decision-makers to engage with how transit agencies use data.
During my fellowship this year I wrote about it on this blog and explored what prioritizing qualitative data would look like in practice at transit agencies. I have turned some of this thinking into a website and training presentation. It focuses on questions to ask about quantitative data analysis, since that is my expertise, and points to when qualitative analysis is needed. I hope people find it useful and I welcome feedback!

Transit recovery requires addressing organizational trauma
My last post on addressing transit agencies’ labor ‘shortage’ got a bit of traction so, here is a follow-up focusing on the need for transit agencies to address the organizational trauma caused by COVID-19. Similar to other employers, in order to retain and recruit employees, transit agencies need to address the emotional impact of the pandemic on their workforce.
Clearly, the COVID pandemic has created immense stress in every community. And the ongoing pandemic has an acute impact on people in jobs that cannot be done remotely and in sectors where the work itself must not stop. The healthcare sector is highly visible coping with both challenges, and every week I see new stories of devastating burn-out.
The majority of public transit work also can’t be done remote and can’t stop. In March 2020, we at the MBTA could not predict what was going to happen, but we knew that we needed to keep running no matter what. Agencies have adjusted service levels, accounting for ridership changes and often in response to employee availability, but have kept operating day in and day out of the pandemic. (These changes take considerable work in and of themselves.)
Many transit workers on the frontlines got sick and hundreds died of COVID. Frontline transit workers have had to accept daily risk and fear of exposing their loved ones. And, to protect themselves and other riders, they have to proactively enforce mask mandates and cope with anger from some members of the public. Agencies had to plan for uncertainty of revenue sources and the possibility of service cuts and layoffs. And staff had to come to terms with the impact cuts would have on riders and the workforce.
Unfortunately, managing through crisis and trauma isn’t new to transit agencies. Just in the year before COVID-19, the MBTA had several major derailments (one impacting service for months), a bus operator fatality, and multiple people struck by trains. I used to say that working at T was like being on a crisis treadmill. During COVID, the other crises experienced by transit systems didn’t stop.
Transit employees are also first responders for passengers in crisis. Policy decisions, like the lack of affordable housing, mental health and drug treatment resources, and growing income inequality, are increasing passengers in need. These decisions, often outside a transit agency’s control, put increasing stress on agency staff to respond on top of their existing jobs.
All of this is layered on top of the everyday trauma of racism and all forms of oppression playing out in the workplace. And in the specific moment of 2020 the societal trauma of killings of Black people by the police and hate crimes against Asians.
By the time the calendar hit the middle of 2020, my emotional reserves from crisis were completely empty. For the rest of the year, I cried at work almost every day. And I was privileged to be working from the safety of my home, which offered the additional grace of being able to turn my camera off.
I left the T at the end of 2020 and it took me months to recover. I imagine that it is even more difficult to be two years into this pandemic with another surge underway. It is no wonder that many employees are at their breaking point or that it is hard to recruit.
Regardless of how long this pandemic lasts, transit agencies have work to do to recover beyond building back ridership and revenue sources. The collective trauma the agency experienced has to be acknowledged and addressed. And in the process, agencies should implement better strategies to deal with trauma in general.
Trauma impacts individuals, and also organizations, communities, countries, and right now the world. I find the concept of organizational trauma useful because it allows us to think about collective impacts and responses. Organizational trauma can start from single events or build over time and if not addressed it can become embedded in organizational culture.
Much of the writing on organizational trauma focuses on mission-driven nonprofits that serve people in need (e.g rape crisis centers). While some of the specific takeaways might not apply, there are parallels with the mission-driven nature of public transit agencies. Transit employees provide direct public service and their commitment to service can mean organizational crises become personal ones.
Workplaces often provide individual responses to trauma like HR hotlines or therapy referrals. Transit agencies often have in-house teams to provide employee services and support. While necessary, these services don’t solve problems that are ingrained in organizational culture and management practices. Recovery from the current level of trauma requires institutional changes.
After a major derailment in 2019 the MBTA Board (FMCB) hired an independent panel to review the safety practices and culture and make recommendations. At their kick-off meeting with the senior management team, the panel asked us what we thought we did well as a team. As we went around the room the most common answer was respond to crisis. This might be because we had so many, but at some point it becomes a bit of a self-fulfilling prophesy. When your identity as a leadership team is crisis response, who is focused on crisis prevention?
Almost* no matter what happens on a given day, transit agencies have to start over the next day and try to do the same thing- run the schedule. There is not much time for reflection and when it happens it is often focused on technical changes to make. (COVID did make some transit agencies more adaptive as they figured out how to adjust service levels in response to crowding on a daily basis.)
Even though the work is the same, the next day isn’t the same as the day before for the people running the schedule. People’s lives change, sometimes in acute ways. After the mass shooting at the VTA yard in San Jose in May 2021, a horrific trauma for their workforce, the acting GM Evelynn Tran said something that has stayed with me. She said, “Some of us get training on what to do when there is an active shooter event, but not about the aftermath.” In my years at the MBTA, I did a few trainings on active shooter events and the simulation ended when the shooting stopped. But an event like that is only the beginning of trauma; I never had a training on what to do after a crisis. As a manager responding to personal and collective crisis at work, I relied on the training and experience I received as a volunteer at a rape crisis center years ago.
When organizations don’t train their managers to respond to crisis and the aftermath, that means the work isn’t always happening when it should, leaving employees unsupported. And it means that the people who are doing this work aren’t being recognized or compensated for their emotional labor. They are the ones who are counseling colleagues when someone had a particularly bad day and their manager doesn’t want to hear about it. They are the people who mentoring and training new employees, even though it isn’t in their job description or rewarded with pay raises and promotions. They are the managers who speak up for their team, but have no one to turn to. Often women and people of color are over-represented in the group shouldering the organizational trauma. Before COVID I used to joke that I held therapy office hours from 5 to 6pm. But I don’t think it is funny anymore.
This group of care-givers is providing an emotional buffer for the rest of the organization, allowing others to not feel the full impact and keeping the organization emotionally afloat. Not only is the labor not recognized, but the responsibilities aren’t spread evenly reinforcing gender and race-based inequities. This is unhealthy for the individuals and for the organization. In times of mass trauma, like COVID, this informal system can no longer carry the load. Ways to address trauma and crisis have to be built into the systems and structures of the organization.
One very practical example of a system impacting employees at a transit agency is scheduling. Transit agencies have the ability to create better work-life balance for their frontline employees by how they schedule shifts, off-days, and breaks. I heard from a few folks after my last post that people are quitting because of how work is being scheduled. Efficiency has to be balanced with employees’ needs. This balance can be thrown off in the name of cost-savings and need adjusting. But even if the scheduling practices haven’t changed, I think the balancing point needs to shift to account for the trauma and general exhaustion of the past two years. I found some helpful content on LinkedIn on retention and scheduling.
Even after COVID has receded transit agencies will continue to face crises, and how they respond will determine if they are on a crisis treadmill. Resources and leadership attention have to be dedicated to preventing crisis and responding to the emotional aftermath of crises. Everyday management practices need to include sharing the emotional labor more equitably and prioritizing employee wellness in systems. They are probably pretty busy right about now, but there are experts in organizational trauma who can help.
Transit agencies are going to have to change to recover from the COVID pandemic. They need to change their service to better serve the public. Many will need new revenue sources. And transit agencies need to change their organizational culture to recruit and retain their workforce. Many of these changes needed to happen before, COVID made the need more visible. COVID also showed that transit agencies can respond and change more quickly.
*For example, the VTA shutdown their light rail service for months after the mass shooting. A decision I supported, but for which they faced public push back and had a big impact on some passengers.
Solving the operator ‘shortage’ by not running transit like a business
In my second dating app message to my now partner I shared a link to this New York Times article. I was responding to the question, “what are you doing today?”, and I said reading this article and thinking about how it applies to the public sector. The article compares the career path of a Kodak employee, who started in the 1980s as a janitor and become CTO, to a person who works now as a subcontractor janitor at Apple without employee benefits or promotional opportunities, to illustrate how changes in corporate practices contributed to income inequality. Lucky for me, we are still talking about the article together!
Right now I am thinking about it in the context of the current crisis in the public transit sector to hire enough frontline employees, especially bus operators, which is causing service reductions across the country. The problem of not enough bus operators existed before the pandemic, but as you can imagine the risk of COVID and increasing operator assaults makes the job even less attractive. There are many possible other factors like increasing opportunities as delivery drivers who don’t need to interact with passengers. (I also heard a theory about the impact of federally required random drug testing for transit employees.) I think to solve the problem holistically, we need to understand the changes in the US economy illustrated by the NYT article and implement long-term solutions that reverse these trends.
Stories like Gail Evans’s rise at Kodak were always rare, but these stories were the exceptions that held up the dream of the US economy as a meritocracy. At this point they are almost non-existent in large private sector firms, but it is still possible in a public transit agency for someone to start at the frontlines (e.g. bus operator) and work their way to the top. In the past the MBTA had bus operators become General Manager. The current head of King County Metro Terry White started at the agency as a telephone operator. At the MBTA I saw the immense value of working with people who had started at all levels of the agency and the knowledge they brought to the team.
The public sector in the U.S., which maintained higher unionization rates than the private sector, has historically served as a pathway to the middle class, especially for Black Americans. But throughout my lifetime (I was 1 when President Reagan fired the air traffic controllers) there has been increasing pressure on public sector unions and attempts to maintain/lower public sector costs in order to maintain/lower tax rates. It is commonplace to hear politicians and business leaders alike say that we should run government like a business.
During my time at the MBTA, mostly between 2015 and 2018, I got to see running government like a business in practice. There was a concerted effort to lower the cost curve by using strategies from the private sector that limit upward economic mobility. The most visible efforts were the attempts to outsource some internal jobs. Outsourcing was successful for cash collection jobs, customer service agents (now the red jacket ambassadors), and warehousing. And attempts to contract out some bus operations and bus maintenance jobs were used as leverage in union negotiations, including the 2016 ATU contract that lowered starting wages for bus operators in exchange for not outsourcing.
As in the example at Apple, outsourcing meant that, along with any lower wages or benefits, workers in the outsourced positions likely have a limited career pathway with the private employer. Previously, an employee could have worked as a customer service agent during a long career at the MBTA, but today, being a T Ambassador is less likely to be a stepping stone in a career than a short stint in a string of low-wage jobs.
A less externally visible private sector practice in this time period was hiring more executives who were generalists (experts in management), instead of hiring experts in transit operations or training existing workers in management skills. To try to understand my new colleagues I did a lot of reading about the rise of the MBA. Most of it connected changing management strategies in the private sector to the shift from an economy based on producing things to consuming things (a financial and service sector economy). I found fewer resources on the impact/extent of MBA management in the public sector. (If you know of sources, please share them!)
I suspect that the desire to have ‘professional’ managers is, at least in part, to create an experience barrier between executives and workers under the theory that someone who worked their way up would be less inclined to cut costs in ways that impact the people following behind them. Regardless of the motivation, the impact is a limit on the upward career mobility of the workforce and decrease in the incentives to invest in their professional development. In transit agencies like the MBTA this increases the demographic divide between the frontline workforce, which is predominantly people of color, and management, which is significantly white.
Riding a bus in 2017 I had a conversation with an MBTA bus operator who spoke pointedly about the operations and management divide. After seeing my employee badge, he opened up about how he had been at the T for 17 years and it used to be that someone could work their way up from bus operator to GM, but he couldn’t imagine it happening now. It felt like there was an increasing divide between operations where most managers had worked their way up and the executive team where most people didn’t know the business.
Part of the larger economic shift illustrated in the Kodak and Apple story is the decreasing amount of time that people expect to stay with an employer. People stay longer in public sector jobs and I suspect it is partially due to availability of retirement and pension plans. I believe that if the pension disappeared tomorrow, the MBTA would lose even more talent and would have a bigger operator shortage. However, it isn’t a sign of a healthy, robust workplace if people are mostly staying for the pension.
With the pension, even with a lower starting wage, the MBTA is a better employment choice than driving for a private company if you plan to stay for 25 years. But I wonder how much that factors into people’s employment decision-making right now, especially if a transit agency doesn’t seem like a place you want to stay for a career. (I am not an expert on pension financing, but it is worth noting that at the MBTA, executives are given a choice between joining the pension or a retirement plan where you are fully vested in 5 years; but non-executive workers don’t have the retirement plan option.)
Another pivotal change in the post-1970’s U.S. economy was a shifting of the burden of job training from companies to individuals through higher education, which is increasingly financed by personal debt. With the drop in accessible pathways to secure middle-class jobs in the private sector came a marked increase in people from working class families attending post-secondary schools with aim to receive training and credentials that would allow them to access jobs with greater potential for economic advancement and stability. Not only did this shift create an epidemic of education debt, it under-emphasized the value of technical trade jobs leaving a shortfall in the workforce needed in the infrastructure sector in the US as the existing workforce retires.
The NYT article ends with the observation that in the 21st-century economy the reality for most workers is: “Rather than being treated as assets that companies seek to invest in, they have become costs to be minimized.” The Great Resignation brought on by the pandemic should be a clear sign that this economy is untenable. Public transit agencies should be in a good position to attract job seekers since they have the foundation for career pathways, benefit packages, and on-the-job training programs. Instead of borrowing a cost-cutting mentality from the private sector, they need to invest in their workforce. These investments need to be in long-term structural and culture changes, in addition to short-term measures like wage increases, work rule changes, and addressing immediate safety concerns.
The investment needs to start in K-12 education with curriculum about infrastructure careers and pathways through technical training as well as higher education. Infrastructure is literally community building and the rewards of a career in a public transit agency can be mixed into learning about civic participation, climate science, and technical skill building. Introducing Youth to America’s Infrastructure is developing and piloting curriculum as a model.
Transit agencies need to invest in professional development at all levels so that not only is it possible, but it is a goal that people starting on the frontline reach management levels. Making transit agencies a place where everyone can advance (and want to stay for a career) also requires addressing underlying racism, sexism and toxic workplace cultures so they are healthy and safe places to work. I am encouraged by VTA’s actions after a workplace shooting earlier this year, King County’s equity and social justice workforce goals and SFMTA’s racial equity plan. And I know other agencies around the country are creating internal equity teams to do this hard culture changing work.
Yes, these investments will require additional public resources for public services like transit. But these people focused investments outweigh the costs when we measure all the benefits. In addition to quality and reliable public services, pathways to economic mobility and equitable and inclusive public sector workplaces help address income and racial inequality in the US.
Part 2: Qualitative Data Infrastructure and Research Methods
In Part 1 I talked about my experience using quantitative research methods at the MBTA. Over the past almost a year I have thought (and read) more about qualitative research and data (and the difference between the two).
For transit agencies to really consider and use community voices and lived experience as data they will need to institutionalize qualitative data and research methods. This will require different data infrastructure, data collection, and analysis skills.
In general transit agencies gather qualitative data for a particular project, plan, or policy decision as one-off efforts. Each effort sometimes regathers the same input from the community as previous ones. This can be a burden on both the community and the agency’s time. Part of the problem is that transit agencies (transportation more widely) don’t have a qualitative data infrastructure.
As agencies started getting more automated data from technology systems they developed data infrastructure to clean and store data. They hired IT staff to build and maintain data warehouses and data scientists to analyze the data. They built dashboards that visualize the data. Part of what this data infrastructure allows is for multiple teams to use the same data to answer different questions. For example, ridership data is stored in one place and many departments (and agencies and organizations) can access it for their analyses. The data infrastructure also provides transparency with open data.
In my experience transportation agencies don’t have the same infrastructure for qualitative data. There isn’t a centralized location and a storage system so multiple teams can find out what riders on a certain route or neighborhood are saying. The data from the customer call center remains siloed in that system. The input for a specific project stays with that project team. Data from the transit agency isn’t shared with the MPO or City. Or the public in a standardized way.
At the MBTA we did create an infrastructure for survey data. My team wrote an internal survey policy to standardize practices and data sharing. Part of this effort was standardizing basic questions so we could gather comparable results across surveys and time. This ‘question bank’ also allowed us to save time and money by getting all of our standard questions translated into the six languages the MBTA uses (based on its Language Access Plan) once. We attempted to create a single repository for survey data. (Most of the work to do this was organizational, not technical.)
Creating this type of qualitative data infrastructure requires thinking through data formats, how to code qualitative data (by location, type of input, topics, etc), and how to share and tell the stories of the data. And whoever is doing that has to have authority to impact all of the ways the agency gets community input. So importantly creating this infrastructure is also about where community engagement lives in an agency and how it is funded.
(An advocate I spoke to recently suggested that maybe this consolidation of qualitative data shouldn’t even live at a transit agency. That it should cut across all transportation modes and live at the MPO or other regional body.)
To move beyond using qualitative data in quantitative analysis, agencies need people with research and data collection skills not always found in a transit agency. Lots of agencies have started hiring data scientists to analyze their ‘big’ quantitative datasets. Agencies also need sociologists, ethnographers and other research skillsets grounded in community. These researchers can design community data collection efforts that go beyond public comments in a public meeting.
Qualitative research also asks different questions. Instead of using data to explain who is in the tail of a quantitative distribution, qualitative research asks questions like why is the distribution like this in the first place and how do we change it. Qualitative research is able to bring in historical context of structural racism, explore the impact of intersectional identities, and allows power dynamics to part of the analysis. Check out more from The Untokening on the types of questions that need to be asked.
Transit agencies often aren’t asking the types of research questions that qualitative research answers. Not just because they don’t have the staff skillsets, but because these questions don’t silo people’s experiences with transit from their experiences and identities overall. Lots of agencies try to stay in their silos, so they aren’t forced to address the larger structural inequities. It is easier to focus on decisions you think are in your control. For example, quantitative Title VI equity analyses are confined to only decisions made by that agency in that moment in time. But equity is cumulative and no one is just a transit rider.
Valuing community voices as essential data means agencies will need to invest in data collection, storage, analysis, and visualization or story-telling for qualitative data in a manner similar to quantitative data. The executive dashboards and open data websites will need to incorporate both types of analysis and data. More fundamentally it means that agencies will have to breakdown their silo and take an active role in fixing the larger structural inequalities that impact the lives of their riders everyday.
This series is about the data used to make decisions; clearly who is making the decisions is also important to valuing community voices. I chose to write this series in a way that shows how my thinking about data has evolved over time and will no doubt continue to do so. In fact it evolved in the act of writing this! For insightful dialogue about revision in writing and life, check out this podcast between Kiese Laymon and Tressie McMillan Cottom.
Part 1: Mixing Qualitative Data into Quantitative Analysis
One of The Untokening Principles for Mobility Justice is to “value community voices as essential data.” I have been thinking about how transit agencies can put this into practice.
This is a three-part series that shows my thinking about data over time. The prequel is the post I wrote on data back in 2017 that mostly focused on how messy quantitative data analysis is. In Part One I discuss my experience in a transit agency mixing quantitative and qualitative data for analysis using quantitative research methods. Part Two is my thinking now on the importance of qualitative research methods and what transit agencies need to do to put qualitative data on equal footing with quantitative data. (Note: I have found a distinction between qualitative data and qualitative research methods useful as my thinking has evolved.)
Quantitative transit data often comes from technology systems (e.g. automated passenger counters or fare collection systems) or survey datasets (e.g the US Census or passenger surveys). In both cases collecting quality data requires investment. The benefits of technology systems are datasets that contain almost all events (a population, not a sample) and the ability to automate some analysis. However, transit agencies can’t rely on technology systems alone, because there is so much information, quantitative and qualitative, that these systems can’t measure.
As a generalization, qualitative data is information that is hard to turn into a number. For quantitative transit analysis, it is needed to answer questions about how people experience transit, why they are traveling, trips they didn’t make, and how they make travel decisions. Qualitative data can come from surveys, public comments at meetings, customer calls, focus groups, street teams, and other ways that agencies hear from the public directly.
In the data team at the MBTA we knew we needed both quantitative and qualitative data, usually mixed together iteratively depending on the type of decision. As an oversimplification, we used data to measure performance, find problems, and to identify/evaluate solutions.
Before you measure performance, you have to decide what you value (what is worth measuring) and how you define what is good performance. Values can’t come from technology and should come from the community. At the MBTA the guiding document is the Service Delivery Policy. In our process to revise this policy, we used community feedback in the form of deep-dive advisory group conversations, a survey, and community workshops. Once we agreed on values, knowing what data we had to measure those values, we needed input to try to make the thresholds match people’s experiences.
For example, we valued reliability so wanted to measure that in order to track improvements and be transparent to riders. This brings us to the question of how late is late? Our bus operations team stressed that they need a time window to aim for due to the variability on the streets. From passengers we need to know their experiences like: is early different than late, do they experience late differently for buses that come frequently vs infrequently, and how they plan for variability in their trips. Then we worked with the data teams to figure out how to build measures using the automated vehicle tracking data to report reliability and posted it publicly every day.
Identifying problems can come from both community input and data systems. Some problems can only be identified through hearing from passengers. No automated system measures how different riders experience safety onboard transit or tells transit agencies where people want to travel but can’t because there is no service or can’t afford it. In some cases, automated data is far more efficient in flagging issues and measuring the scope and scale of problems. For example, we used automated systems to calculate passenger crowding across the bus network and where it is located in time and space.
The MBTA used quantitative data to identify a problem of long dwell times when people add cash to the farebox on buses. The agency decided on a solution of moving cash payment off-board at either fare vending machines (FVMs) or retail outlets. (I will admit more qualitative analysis should have been done before the decision was made.) It was critical to understand how this decision would impact the passengers who take the 8% of trips paid in cash onboard. We used quantitative data on where cash is used to target outreach at bus stops. We did focus groups at community locations. Talking to seniors we found that safety was a key consideration between using a bus stop FVM or retail location. This is the type of information we could have never gotten from data systems or survey that didn’t ask the right questions. The team used the feedback to shape the quantitative process for identifying locations.
A key question is at what points in a quantitative analysis process can agencies rely on quantitative data and when is qualitative data imperative. As a generalization, quantitative research methods aggregate data and people’s experiences. We aggregate to geographic units (e.g. census blockgroups) and to demographic groups. We look at the distribution of data and report out the mean or some percentile. Quantitative data analysts need to look at (and share) the disaggregate data by demographics/geography before assuming the aggregated data tells the complete story. And ask themselves, when do we need more data to understand the experience in the tail of the distribution and when is the aggregated experience enough for making a decision.
The question of the bus being late and the use of cash onboard illustrate this difference. Once we set the definition of reliability, service planners use quantitative data to schedule buses. Looking at a distribution of time it takes a bus to run a route, you know there is going to be a long tail (e.g. long trips caused by an incident or traffic). Even though the bus will be late some percent of the time, it is an efficient use of resources to plan for a percentile of the distribution. Talking to the people who experience the late trips would be useful, but likely wouldn’t change that service is planned knowing some trips will be late. (Ideally riders, transit agencies, and cities work together to reduce the causes of late trips!)
However, on the question of cash usage, looking at the payment data you can’t ignore the 8% of trips paid in cash. The experience of that small group of riders is critical. Likely riders paying in cash rely on transit, experience insecurity in their lives, and a decision to remove cash onboard is a matter of access. Without talking to riders, we have no data on why they pay in cash, what alternative methods to add cash would work best for them, and the impact of having to pay off-board.
In my current thinking, at a minimum, decisions that impact the ability of even a small number of people to access transit or feel safe require a higher threshold of analysis. Agencies shouldn’t rely solely on aggregate quantitative data and need qualitative data on the impacts. The role of transit (and government in general) is to serve everyone, including, and often especially, people whose experience fall in the tail of a distribution. (A very quantitative analysis view of the world, I know.)
The lived experience of the community is critical to transit agency decision-making. There are many types of data that can’t come from automated systems. In my experience transit agencies should mix qualitative data into quantitative data analysis, often iteratively as the data inform each other. In practice this means that the teams doing quantitative analysis and community engagement need to be working in tandem with the flexibility to adjust as new data changes the course of the analysis.
Prequel: Data Thoughts
(Written May 2017)
Data driven decision-making is the buzz phrase in government and with all the ‘big data’ available it has great potential to improve outcomes. But I don’t think most people have a good idea about what it means in practice or how to understand its limits.
The irony is that I studied pure math in college because I wanted absolutes and to find a kind of truth. I loved proofs, because there is an indisputable answer. And now I spend my days wading around in data, which is all some amounts of wrong, and trying to figure out how to best use it to guide decisions.
Here are a few overly simplistic conclusions I have drawn from my team’s work over the past two years.
Data isn’t clean
There is a tendency to think numbers are true, but in reality they are estimates. The challenge is figuring out how close of estimates and how to make them closer. Often the data we have isn’t being generated to measure the thing we want to measure; it is a byproduct of a different process we are trying to recycle.
We constantly have what we call ‘data mysteries.’ This is when common sense makes us think the data is missing or wrong, and we have to figure out the cause of the problem. Maybe there are software problems. Or we miscoded something along the way. Or the data just isn’t being collected in the way we thought.
Context is critical
Making information out of data requires a lot of context. We can’t find the problems with the data without knowing how the data was collected and the directions of possible errors. We need to know external variables that could be causing change.
We need to understand the problem we are trying to solve so we can identity the best datasets and types of analysis to answer that question. This determines the exact variable, the levels of aggregation, the timeframe for the dataset, and any number of other factors.
Lastly, the results require context. We might say that approximately 34% of trips won’t be impacted, but this will require four footnotes to explain the exact conditions under which we think this to be accurate.
Data analysis isn’t linear
It would be nice if the process went something like: define a problem, find clean data, analyze it, propose best solution. But it isn’t a linear process. Sometimes we find data and play around with it to see if it can tell us something interesting. Other times we have a problem and we don’t have data, so we try to collect some or find something that might approximate it. Often there is already a proposed solution and we are trying to check the impacts.
Analysis is a maze (if not, you are probably presupposing the answer). We are constantly making the best guess of which pathway to take, running into dead ends, finding data problems, and when we arrive at an answer it is likely only one of many paths. We can hope that no matter what path we took that the general conclusions would be the same; but, depending on the dataset, it isn’t a guarantee.
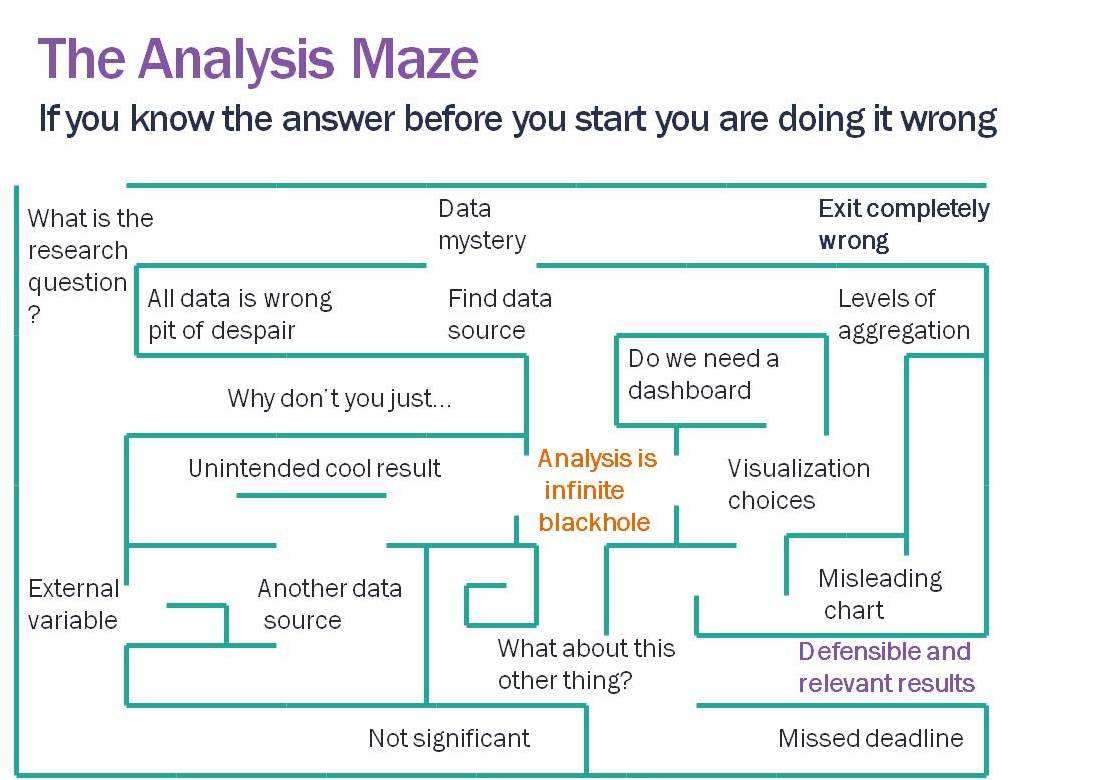
The results aren’t static
Just like writing there are drafts, but eventually we declare it good enough. And often there are mistakes. New data shows up which points out a problem with our original dataset. We figure out a new method. We realize we missed something or made a formula error.
We can hope we are at least asymptotically approaching ‘the answer.’ But we need room to get there. Being honest about data requires forgiveness.
Data isn’t everything
Our understanding of problems to be solved shouldn’t be limited by the data we have. And just because we have data on something doesn’t mean there is a problem to be solved with it.
For example, it is easier to estimate people’s wait times on subway platforms than at bus stops. But that doesn’t mean subway wait time reliability is more important than bus. Qualitative data (aka actually talking to people) is critical to finding problems and solutions.
We have all sorts of systems that generate millions of records of data a day. But the existence of data doesn’t eliminate the need to have a conversation about whether/how we should be using it.
Data literacy
Data does have the power to help governments to make better decisions. We can measure impacts of policy decisions. We can disprove conventional wisdom. The results can change (and improve) outcomes. In order to have this impact, decision-makers, members of the public, and journalists all need to be better data consumers.
This means reading the warning labels that come with a dataset to understand the context. It means appreciating all of the complexities and uncertainty in the process. It means allowing the time and space to find mistakes. But most of all, it means being open-minded and not allowing our implicit assumptions to overwhelm our curiosity about what the data can tell us.
Data is not a truth, it is very messy. But acknowledging and appreciating the mess makes the analysis far more likely to be accurate in the end.
